1. RFM 분석
RFM 고객 분석하기 위한 피처를 R,F,M 피처를 가지고 고객을 이해/분석하는 방법론이다.
Recency : 얼마나 최근에 구매했는가
Frequency : 얼마나 자주 구매했는가
Monetary : 얼마나 많은 금액을 지출했는가
RFM 지표 도출 방법
RFM 지표 도출 단위는 고객 한명이다. (customerID로 groupby)
| Recency(R) | 가장 최근 구매한 상품 구입일과 현재 기준까지의 기간 | # 현재 날짜 설정 current_date = pd.to_datetime('today') # Recency 계산 df['InvoiceDate'] = pd.to_datetime(df['InvoiceDate']) recency_df = df.groupby('CustomerID').InvoiceDate.max().reset_index() recency_df['Recency'] = (current_date - recency_df['InvoiceDate']).dt.days |
| Frequency (F) | 고객별 주문 횟수 | df.groupby('CustomerID').Invoice.nunique() |
| Monetary(M) | 고객의 총 구매금액 - 각 거래의 구매 금액을 계산(Amount = Quantity * Price) > 고객 별 주문 금액을 합산 |
df['TotalPrice'] = df['Quantity'] * df['Price'] monetary_df = df.groupby('CustomerID').TotalPrice.sum() |
RFM 분석 시 유의사항
- 분석 기간 설정
RFM 분석의 Recency, Frequency, Monetary 지표를 계산할 때 사용하는 기준은 매우 중요하다.
Recency의 경우 현재 날짜를 기준으로 할지, 특정 이벤트 날짜를 기준으로 할지 결정해야 한다.
분석 기간에 따라, Frequency와 Monetary 지표 또한 분석 기간을 어떻게 설정하는지에 따라 달라진다.
RFM 분석은 다양한 산업 분야에서 사용될 수 있다. 각 도메인의 특성에 맞게 RFM 지표를 커스터마이징 해야 한다.
- RFM Feature 추가
RFM 분석은 Recency, Frequency, Monetary 세 가지 지표를 기반으로 하지만, 고객 만족도 지표를 추가하는 등
고객 세그먼트를 위한 다양한 피처를 포함하여 분석할 수 있다.
Retatil Dataset RFM 군집분석
data : retail data
설명 : RFM 기준에 따라 kmeans 클러스터링을 이용하여 고객을 세분화
라이브러리
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import datetime as dt
# 클러스터링
import sklearn
from sklearn.preprocessing import StandardScaler
from sklearn.cluster import KMeans
from sklearn.metrics import silhouette_score
데이터 불러오기
retail_df=pd.read_excel(io='data/online_retail_II.xlsx')
retail_df.shape
(525461, 8)
데이터 선택
# 영국 고객만
retail_sp = retail_df[retail_df['Country'] == 'United Kingdom']
# 취소반품 고객 제외
retail_sp=retail_sp[retail_sp['Price']>0]
# 주문 취소했으니 주문 수량도 - 인 경우 제외
retail_sp=retail_sp[retail_sp['Quantity']>0]
# 회원만 추출
retail_sp= retail_sp.dropna(subset=['Customer ID'])
RFM 피쳐 생성
#Monetary
retail_sp['Amount'] = retail_sp['Quantity']*retail_sp['Price']
rfm_m = retail_sp.groupby('Customer ID')['Amount'].sum()
rfm_m = rfm_m.reset_index()
rfm_m.head()
# frequency : 각 아이디 당 invoice 개수
rfm_f = retail_sp.groupby('Customer ID')['Invoice'].count()
rfm_f = rfm_f.reset_index()
rfm_f.columns = ['Customer ID', 'Frequency']
rfm_f.head()
rfm = pd.merge(rfm_m, rfm_f, on='Customer ID', how='inner')
rfm.head()# Recency
## datetime 변환
retail_sp['InvoiceDate'] = pd.to_datetime(retail_sp['InvoiceDate'],format='%d-%m-%Y %H:%M')
# 최댓값 기준으로 기간 설정
max_date = max(retail_sp['InvoiceDate'])
max_date
# Timestamp('2010-12-09 20:01:00')
# 차이 계산
retail_sp['Diff'] = max_date - retail_sp['InvoiceDate']
rfm_p = retail_sp.groupby('Customer ID')['Diff'].min()
rfm_p = rfm_p.reset_index()
rfm_p['Diff'] = rfm_p['Diff'].dt.days
# 전체 Merge
rfm = pd.merge(rfm, rfm_p, on='Customer ID', how='inner')
rfm.columns = ['CustomerID', 'Amount', 'Frequency', 'Recency']
Monetary > Amout 로 진행했다.
데이터 분포 파악


Amount Frequency Recency
count 3900.000000 3900.000000 3900.000000
mean 1320.563072 80.300000 91.433077
std 1800.457547 103.783789 97.340524
min 2.950000 1.000000 0.000000
25% 299.775000 18.000000 18.000000
50% 651.460000 42.000000 52.000000
75% 1575.927500 99.000000 137.000000
max 14674.960000 734.000000 373.000000
평균, 표준편차 해석
Amount : 평균이 1320.56이지만 표준편차가 1800.46 > 고객 간에 구매량에 상당한 차이가 있음
Frequency :최소 구매횟수는 1회이고 최대 구매횟수는 734회 > 고객 간 편차가 심함
Recency : 평균이 91.43일이지만, 표준편차가 97.34로 다소 큼
평균, 중앙값 해석
Amount, Frequency : 각각 평균과 중앙값의 차이가 큼
Recency : 3 피쳐 중 가장 왜곡 정도가 덜하다.
RFM 3 피쳐 모두 한쪽으로 치우쳐진 왜곡된 분포 형태를 가지고 있었고, 각 피쳐간 스케일이 다르다는 것을 확인했다.
거리기반 알고리즘은 kmeans 알고리즘을 사용해서 군집화하기 때문에, 스케일링은 필수이다.
IQR 이상치를 우선적으로 제거해줬기 때문에 Min-Max Scaler 보다 Standard Scaler를 사용해줬다.
왜곡 정도가 심한 Amount , Frequency 피쳐에 대해서는 추가적으로 로그 변환 후 표준화를 고려했다.
로그 변환 후 표준화

표준화
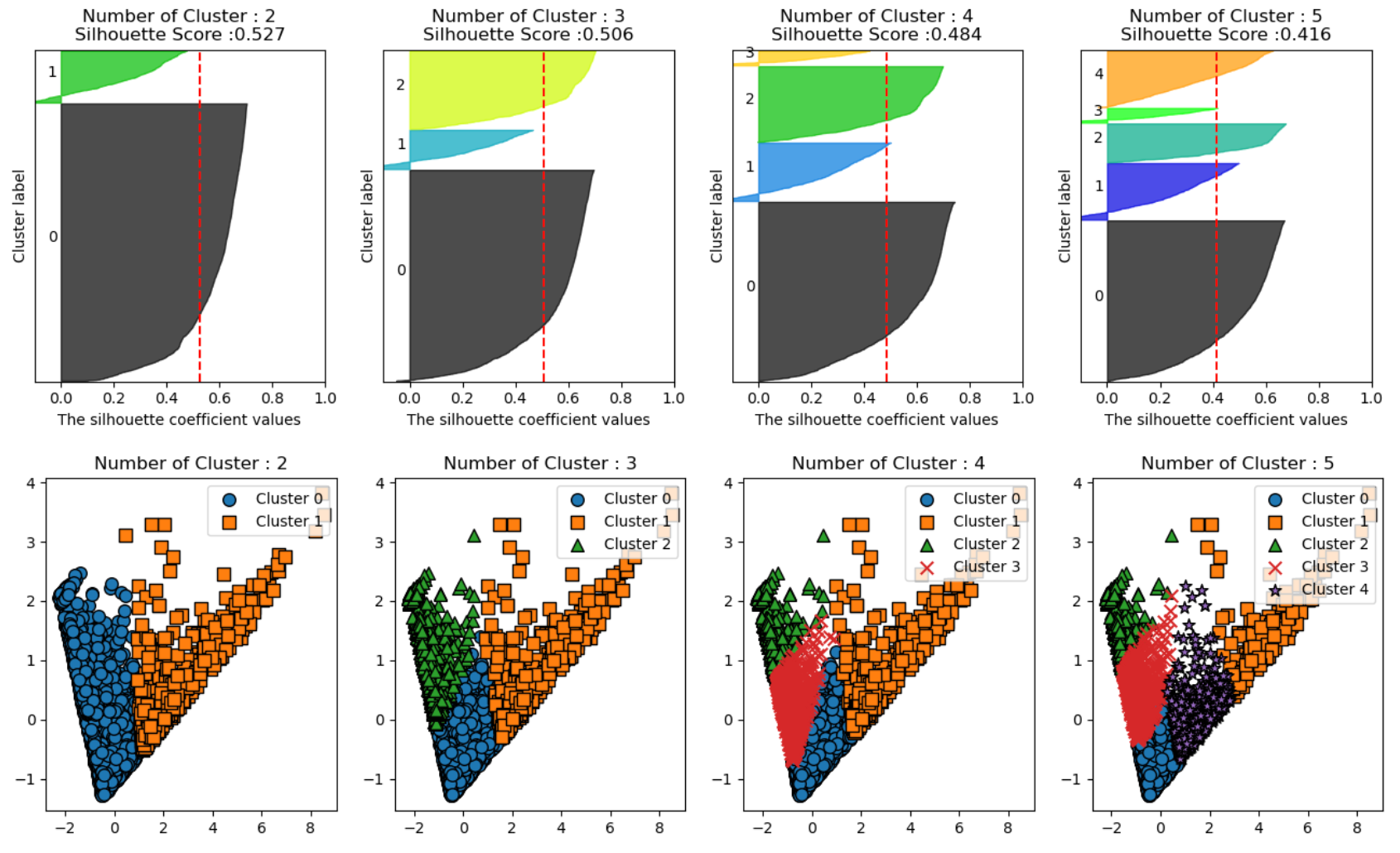
먼저 로그변환을 한 후에 표준화를 해준 데이터셋이 응집도와 분리도를 기준으로 한 실루엣 계수만 봤을 때는 다소 점수가 낮지만, 표준화한 결과가 더 실루엣 결과가 불규칙적이었다. 이것은, 개별 군집의 평균값의 편차가 크다는 것이고, 클러스터링 알고리즘이 데이터의 분포를 고려하지 못하여 잘 분리하지 못하다는 것을 의미한다. 따라서 로그변환 한 후의 데이터셋을 가지고 클러스터링 하는 것으로 결정하였고, k 개수는 Elbow Method 를 추가로 고려하여, 3으로 결정했다.

클러스터링 결과
# 3D 시각화 함수 정의
def plot_3d_kmeans_clustering(df, clusters, k, title):
# 3D 시각화
fig = plt.figure(figsize=(12, 8))
ax = fig.add_subplot(111, projection='3d')
# 산점도
scatter = ax.scatter(df[:, 0], df[:, 1], df[:, 2], c=clusters, cmap='viridis', s=50)
ax.set_xlabel('Standardized Amount')
ax.set_ylabel('Standardized Frequency')
ax.set_zlabel('Standardized Recency')
ax.set_title(title)
legend = ax.legend(*scatter.legend_elements(), title='Clusters')
ax.add_artist(legend)
plt.show()
왼쪽이 로그 변환 하지 않은 클러스터링 , 오른쪽이 로그변환 후 표준화한 데이터셋이다.


클러스터링 결과 Descriptive Statistics

클러스터 0
- R : 대부분 오랜 기간 동안 구매하지 않은 고객
- F :고객은 구매 빈도가 낮은 편이며, 일부 고객은 매우 높은 빈도로 구매
- M :비교적 적은 금액을 지출하는 경향이 있으며, 분포가 넓게 퍼져있음
클러스터 1
- R : 고객은 최근에 구매한 고객이 많으며, 구매 활동이 비교적 활발
- F : 중간 정도의 구매 빈도를 가지며, 일부 고객은 빈번하게 구매
- M :중간 정도의 금액을 지출하며, 지출 금액의 분포는 비교적 고름
클러스터 2
- R : 최근에 구매한 고객이 많으며, 구매 활동이 매우 활발
- F : 매우 빈번하게 구매하며, 지속적으로 많은 양의 제품을 구매하는 경향
- M : 매우 높은 금액을 지출하며, 지출 금액의 분포가 넓음
클러스터별 특징 분석
- 이 고객군들의 주문 제품들은 무엇인지?
- 시계열 - 고객들의 주문 패턴등은 어떤 식으로?
우선 클러스터 결과를 원본데이터 프레임에 합쳐줘야 한다(해당 코드는 생략)
클러스터별 주문 제품 Top 10
# 클러스터별로 품목별 주문 수량 집계
cluster_item_summary = retail_df.groupby(['Cluster_log_standard', 'Description']).agg({'Quantity': 'sum'}).reset_index()
# 각 클러스터별로 상위 10개 품목 추출
top_items_per_cluster = cluster_item_summary.groupby('Cluster_log_standard').apply(lambda x: x.nlargest(10, 'Quantity')).reset_index(drop=True)
# 결과 출력
print(top_items_per_cluster)
클러스터별 월별 주문 추이
# 클러스터별로 날짜별 주문 금액 집계
retail_df['InvoiceDate'] = pd.to_datetime(retail_df['InvoiceDate'])
retail_df.set_index('InvoiceDate', inplace=True)
# 월별 주문 금액 집계
monthly_sales_per_cluster = retail_df.groupby(['Cluster_log_standard', pd.Grouper(freq='M')])['Amount'].sum().reset_index()
# 시계열적 주문 패턴 시각화
plt.figure(figsize=(14, 8))
sns.lineplot(data=monthly_sales_per_cluster, x='InvoiceDate', y='Amount', hue='Cluster_log_standard')
plt.title('Monthly Sales per Cluster')
plt.xlabel('Date')
plt.ylabel('Sales Amount')
plt.show()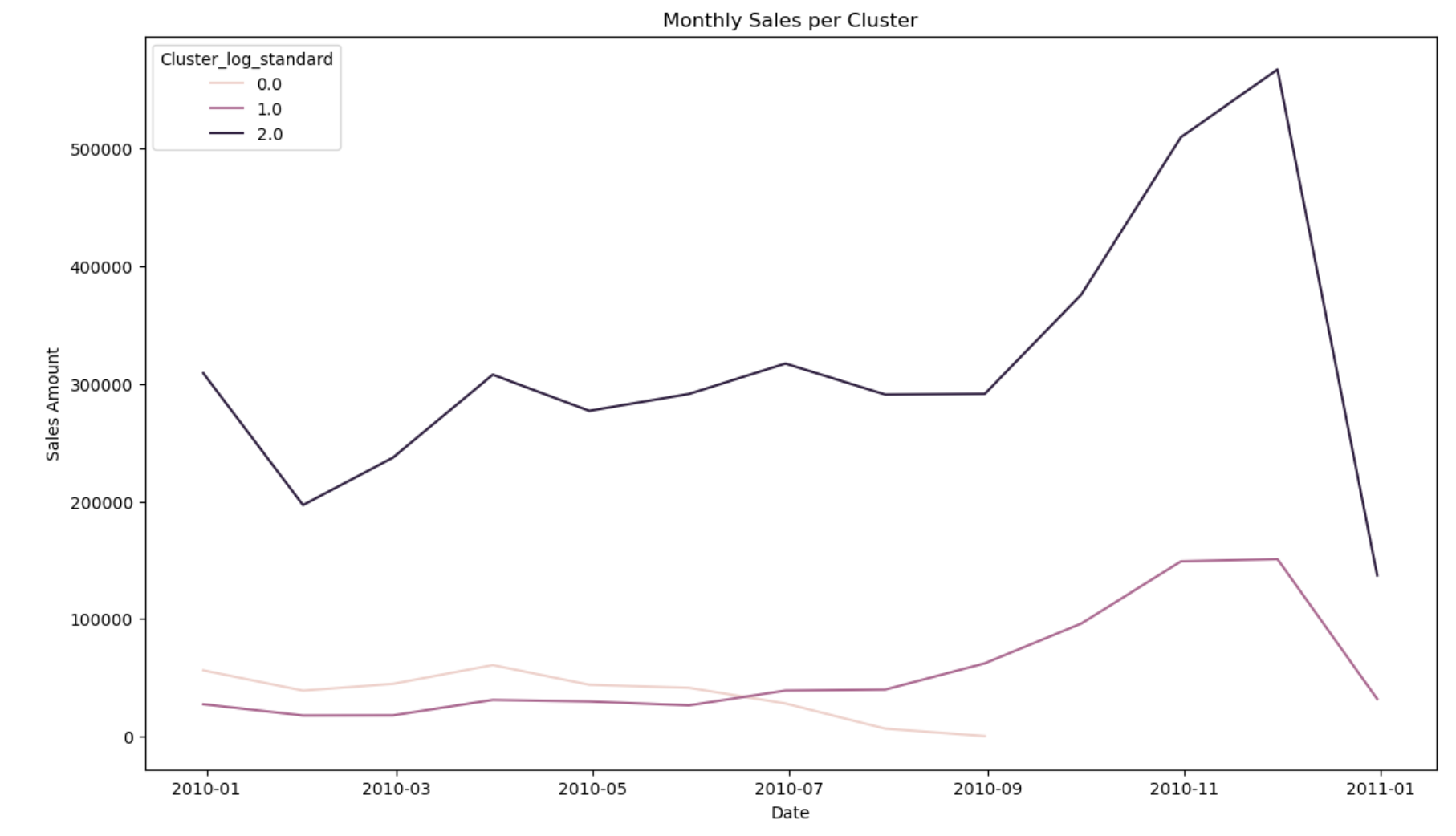
시간대별 주문 패턴
# 시간 정보 추출
retail_df['Hour'] = retail_df.index.hour
# 클러스터별 시간대별 주문 금액 집계
hourly_sales_per_cluster = retail_df.groupby(['Cluster_log_standard', 'Hour'])['Amount'].sum().reset_index()
# 시간대별 주문 패턴 시각화
plt.figure(figsize=(14, 8))
sns.lineplot(data=hourly_sales_per_cluster, x='Hour', y='Amount', hue='Cluster_log_standard')
plt.title('Hourly Sales per Cluster')
plt.xlabel('Hour of Day')
plt.ylabel('Sales Amount')
plt.show()
'Python > Machine Learning' 카테고리의 다른 글
| Regression 손실 함수와 최적화 (0) | 2024.12.08 |
|---|---|
| 가중치 규제 - Ridge,Lasso,Elastic Net (0) | 2024.07.28 |
| K-Means Clustering 알고리즘 (0) | 2024.05.11 |
| KNN 알고리즘 모델 적용 - 하이퍼 파라미터(k값, 가중치) (0) | 2024.05.04 |
| [ML]KNN 알고리즘 (2) | 2024.04.07 |



