728x90
이 포스팅은 < 파이썬 머신러닝 완벽 가이드(개정 2판) >을 학습하면서 정리한 내용이다.(https://www.yes24.com/Product/Goods/69752484)
앙상블 학습(Ensemble Learning)
앙상블 학습이란?
- 여러개의 분류기(Classifier)를 생성하고 그 예측을 결합함으로 싸 보다 정확한 예측을 도출하는 기법이다.
- 대부분의 정형 데이터 분류 시, 뛰어난 성능을 보인다.
- XGboost, LightGBM 등
앙상블 학습의 유형

- 보팅(Voting) : 여러개의 분류기가 투표를 통해 최종 예측 결과 선정(서로 다른 알고리즘의 분류기)
- 배깅(Bagging)
- 랜덤포레스트
- 부스팅(Boosting) : 여러개의 분류기가 순차적으로 학습 수행, 앞에서 수행한 분류기의 예측이 트린 경우 다음 분류기가 올바르게 예측할 수 있도록 가중치를 부여
- XGBoost, LightGBM
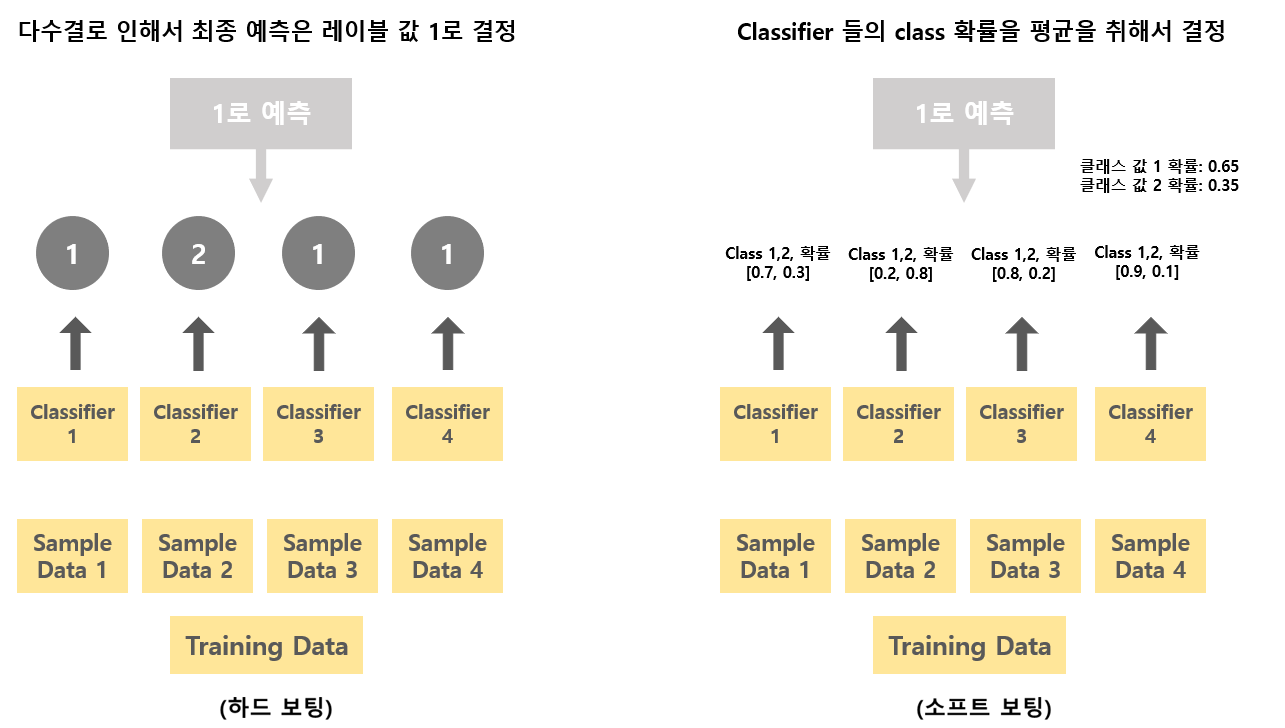
보팅 유형
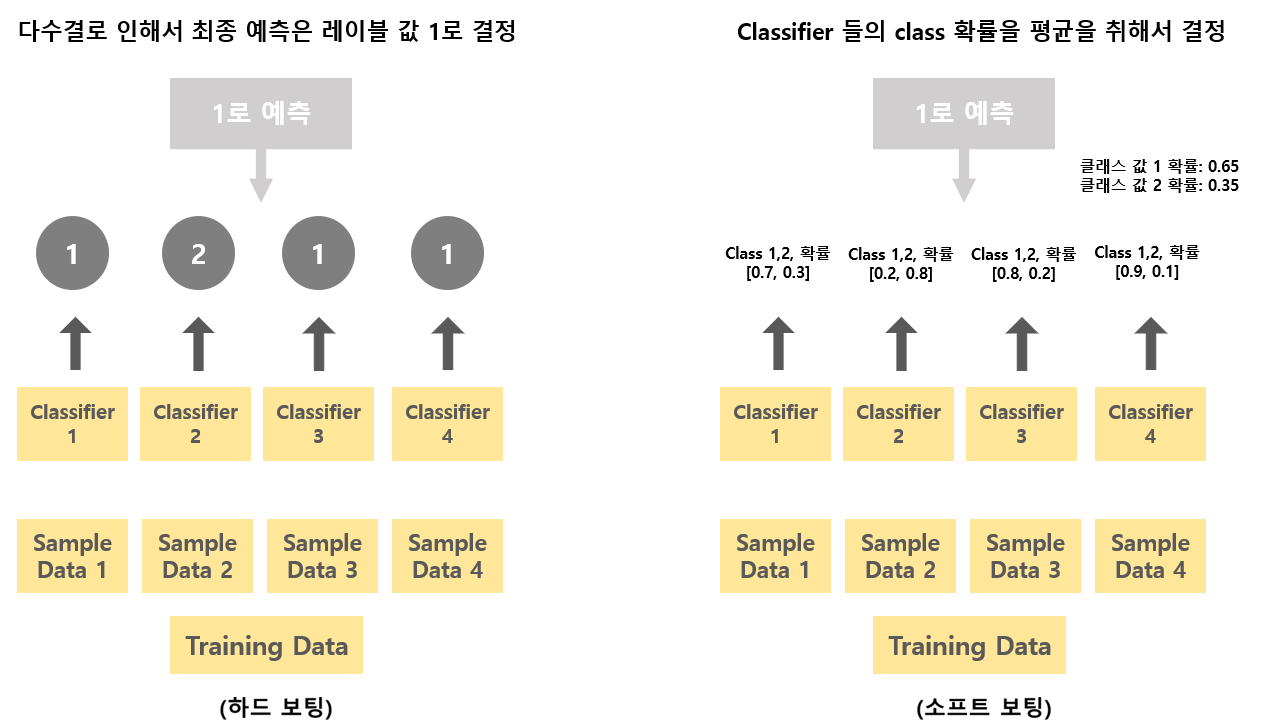
- 하드 보팅 : 예측의 결괏값 들 중 다수의 분류기가 결정한 예측값을 선정
- 소프트 보팅: 분류기의 레이블 값 결정 확률을 평균내서 이 가장 높은 레이블 값을 선정
일반적으로, 소프트 보팅이 하드 보팅보다 예측 성능이 더 좋다.
votingclassifier 유방암 예측 모델 구현
Step 0. 데이터 불러오기 & 라이브러리 임포트
import pandas as pd
from sklearn.ensemble import VotingClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.neighbors import KNeighborsClassifier
from sklearn.datasets import load_breast_cancer # 데이터 호출
from sklearn.model_selection import train_test_split # 훈련/테스트 데이터 분리
from sklearn.metrics import accuracy_score # 혼동행렬 정확도
# 데이터 불러오기
cancer = load_breast_cancer()
data_df = pd.DataFrame(cancer.data, columns = cancer.feature_names)
data_df.head(1)위스콘인 유방암 데이터 세트는 악성/ 양성 종양 여부를 결정하는 이진 분류 데이터 세트이며,
종양에 관련한 많은 피쳐를 가지고 있다..
Step 1. 모델 학습/ 예측 / 평가
사이킷런 의 VotingClassifierVotingClassifier로 보팅 분류기 생성
- 로지스틱 회귀, KNN을 이용
- 객체들을 튜플 형식으로 입력받음
lr_clf = LogisticRegression(solver='liblinear') # 로지스틱 회귀
knn_clf = KNeighborsClassifier(n_neighbors=8) # KNN
# 개별 모델을 소프트 보팅 기반의 앙상블 모델로 구현
vo_clf = VotingClassifier(estimators = [('LR', lr_clf), ('KNN', knn_clf)], voting='soft') # 기본값 : hard
# 훈련 데이터 테스트 데이터 분리
X_train, X_test, y_train, y_test = train_test_split(cancer.data, cancer.target, test_size=0.2, random_state=1)
# 학습/예측/평가
vo_clf.fit(X_train, y_train) # 학습
pred = vo_clf.predict(X_test) # 예측
print('Voting 분류기 정확도: {0:.4f}'.format(accuracy_score(y_test , pred)))- 개별 모델의 학습 예측 평가
classifiers = [lr_clf, knn_clf]
for classifier in classifiers:
classifier.fit(X_train, y_train)
pred = classifier.predict(X_test)
class_name = classifier.__class__.__name__ # 각 모델의 이름 가져오기 # Docstring 문법
print('{0} 정확도: {1:.4f}'.format(class_name, accuracy_score(y_test , pred)))앙상블 학습 방법은 단일 ML 알고리즘에 비해 예측 성능이 좋은 경우가 많다.
728x90
'Data Science & AI > Machine Learning' 카테고리의 다른 글
| [Machine Learning] 하이퍼 래퍼 XGBoost API - 위스콘신 유방암 예측 (0) | 2023.08.29 |
|---|---|
| [Machine Learning] 회귀 , Kaggle 자전거 대여 수요 예측 - 2 (0) | 2023.08.24 |
| [Machine Learning] 회귀 , Kaggle 자전거 대여 수요 예측 - 1 (0) | 2023.08.23 |
| [Machine Learning] 머신러닝 알고리즘 구현 - 붓꽃 품종 예측하기 (0) | 2023.08.22 |
| [Python] 데이터 인코딩 - 레이블 인코딩, 원핫 인코딩 (0) | 2023.08.17 |


