
1. 시계열 데이터의 특성
- 시간이라는 독립변수(고정된 축), 기존 데이터의 특성과는 다른 시계열만의 특성
- 자기 상관관계(Auto Correlation)
- 과거의 데이터가 현재의 데이터에 영향을 주는 경향
- 예) 우리나라 인구수는 자기 상관 관계가 매우 높다

- 추세 경향성(Trend)
- 시계열 데이터의 장기적으로 점차 증가 또는 감소하는 추세

- 계절성(Seasonality), 순환성(Cycle)
- 중장기적인 추세 경향성 외에 날짜나 기간에 따른 주기적으로 변화하는 것
- 추세가 반복되는 변동성 등
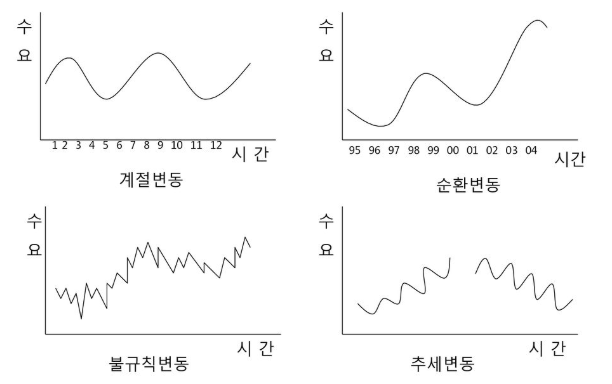
- 불확실성
- 미래의 예측값은 현재로서는 정확히 모른다
- 예측 기간이 길어질수록 예측 신뢰구간이 확장되어 먼 미래의 예측은 더 어려워진다.
2. 시계열 분석
탐색 목적 : 외부 인자와 관련된 계절적 패턴, 추세 설명 인과관계 규명
예측 목적 : 과거 데이터 패턴을 통해 미래 값 예측, 시계열 데이터는 Xt = St(신호) + At(잡음) 형태이며, 잡음을 전처리하여 신호만 잘 학습시킬 수 있도록 함
시계열 데이터 주기성 수치적 확인
ACF (자기상관함수, Autocorrelation Function)
k 시간 단위로 구분된 시계열 관측치 간의 Yt와 Yt+k 간 상관관계를 측정하는 것이다. ACF의 반환값의 절대값이 커질수록 시차 시계열 데이터의 상관성이 크다고 할 수 있다. 이 크다는 것의 기준은 p-value 와 같이 95% 근사 신뢰구간으로 정할 수 있다.
- 시계열 데이터의 주기성을 수치적으로 확인하는데 사용
- 상관계수가 어떤 시간 간격에 대해 크면 해당 시차의 데이터 간에 상관성이 크다고 판단
PACF (편자기상관함수, Partial Autocorrelation Function)
Y의 시점과 특성 t-k의 시점 이외의 모든 시점과의 영향력을 배제한 순수한 영향력을 나타내는 척도
- 시계열 데이터의 시차와 특정 시점 간의 영향력을 나타내는 척도
- 특정 시차 이외의 시간 간격에서의 영향을 배제한 순수한 영향력을 측정
3. ARIMA 모델
ARIMA( Autoregressive Integrated Moving Average) 시계열 데이터를 분석하고 예측하기 위한 모델
모델 작동 원리
- 정상성 확보: 지연과 차분을 통해, 시계열 데이터를 정상 상태로 변환. 즉, 평균과 분산이 일정한 상태로 만들어준다.
- AR, MA 모형 분석 시작 전, 정상성을 만들어준다.( 추세나 계절성이 없는 시계열 데이터로 )
- 차분(Difference) : 현재 상태 값에서 바로 전 상태 값을 빼주는 것 > 모든 기간의 평균을 일정하게 만듦
- 1차 차분 : 추세만 차분
- 2차 차분 : 시계열 데이터에 계절성도 존재하는 경우 계절성의 시차인 n 시점 이전의 값을 빼줌
- 지연 : 정해진 시간만큼 앞으로 당기거나 뒤로 밀어낸 데이터
- 변환(Transformation) : 시계열 데이터의 분산이 일정치 않을 때는 변환을 해준다.(분산이 커지는 경우, 루트)

- AR(Autoregressive) 모델: 과거 시점의 데이터를 사용하여 미래를 예측하는 모델

- MA(Moving Average) 모델: 이동 평균을 이용하여 예측하는 모델

관측값 이전 시점의 연속적인 예측 오차의 영향을 이용하는 방법
해당 시점의 오차항 e에 n시점 이전의 오차항에 이동평균계수를 곱한 값들을 더해준다.
- ARMA 모델: AR 및 MA 모델을 결합하여 사용
모델 각각 사용하는 시점의 수에 따라 두 모델을 결합, 과거 시점의 수치와 변동성을 모두 활용하여 보다 정교한 예측을 수행함
- ARIMA 모델: ARMA 모델에 더해, 시계열 데이터를 정상 상태로 변환하기 위한 차분(Differencing)을 적용
ARIMA(p, d, q)에서 p는 AR의 차수, d는 차분의 횟수, q는 MA의 차수를 나타냄
보통 시계열 데이터는 추세를 가지고 있으며, 일정한 패턴이 있음 > 대부분 불안정한 패턴임.
그래서 모델 자체의 불안정성을 제거하는 기법 ARIMA 사용
시계열의 비정상성을 설명하기 위해 시점간의 차분을 사용함
ARIMA(p,d,q)
- ACF 그래프를 통해 시계열 데이터가 정상 시계열인지 확안히는 것, 시계열 데이터 자체에서 비정상으로 나오게 되면 정상으로 바꿔야 하는 차분 등을 진행
- 그 다음 ACF, PACF 값을 통해 p와 q의 값을 설정
- ARIMA(p,d,q) 모델의 파라미터 작성
요약
AR(p) 모델은 p 만큼 과거의 값들을 예측에 이용하는 것이고, MA(q) 모델은 q 만큼 과거의 오차 값들을 예측에 이용하는 것
따라서, ARMA(p,q) 모델은 p 만큼의 과거의 값들과 q만큼의 과거의 오차 값들을 예측에 이용한다.
ARIMA(p,d,q) 모델은 시계열 데이터를 d회 차분하고(정상시계열로 만들기 위해서) , p 만큼 과거의 값들과 q만큼의 오차의 값들을 통해 수치를 예측하고 차분한 값을 원래 다시 원래의 값으로 반환하여 최종 예측값을 산출한다.
'Data Science & AI > Data Analysis' 카테고리의 다른 글
| Python 대용량 데이터 처리 파라미터 - Pandas (1) | 2024.02.01 |
|---|---|
| Kaggle 시계열 데이터 분석 (2) | 2024.01.27 |
| Correlation Analytics - 상관계수, 공분산 계산 (0) | 2023.12.01 |
| 다중 시각화 그래프 (matplotlib, gridspec, seaborn) (1) | 2023.12.01 |
| [Python] 시계열 데이터 결측치 처리 (0) | 2023.10.08 |


